")

“I believe in facts, science, and reason.”
I used to hear that a lot growing up, especially in college, whenever I would talk about religion. As if people who believed in religion couldn’t also be logical.
Sidebar:
My undergrad degree was in philosophy, and analytical logic was one of my concentrations.
But still, it seems that the atheists try to claim the logical high-ground when it comes to the story of where humans came from. So, over the next four posts, I want to unpack just a little bit of the so-called facts of their argument. The “scientific” perspective.
Sidebar:
I want to be clear that this is not a proof of God (see my prior post for that. Nor is it intended to be a defense of the Young Earth position. (I don’t support that idea, either, but more on that later.) I’m tackling this one to show that the so-called “scientific explanation of human origin” is nowhere near as logically cohesive (or scientific) as most of its believers, advocates, and patrons think it is.
One more note to the preface: the origin of life on this planet is not “observable science”. This topic falls into the realm of theoretical science. What’s the difference? Observable science can be readily witnessed and demonstrated repeatedly. “Gravity” is observable. Even though gravity is a theory, it can be demonstrated and observed. Just drop a pencil, and chances are, it will land on the table or floor. “Theoretical science” encompasses things that cannot be observed. We only have ideas about them based on either 1.) observed things that are similar, or 2.) what really amounts to the ideas and musings of (hopefully) very smart people.
A good and universally-accepted judge of the soundness of theories is how well they mesh into either observable happenings, or other generally-accepted theories. In cartoons, the coyote drops the anvil, but it never falls when he releases it – only when he’s standing under it. For a cartoon, this is fine, but if it happened in real life, we’d all have to re-examine our concept of gravity. And our collective ambivalence toward anvils.
We allow cartoons to break their own rules because we don’t expect them to be realistic. Unfortunately, it seems that within the “scientific” (and by “scientific” I mean “God-less”) explanation of the universe, a similar pattern of rule-breaking is generally accepted.
Sidebar:
In science, “laws” are better than “theories”. Since “gravity” is only awarded theory-status, you’d think “laws” would have to be pretty darn certain, right? For the most part, they are, but as my scientist friends inform me, even laws occasionally get overturned. Go figure.
First up, the Big Bang. Now, to be clear, when it comes to the Big Bang, the Catholic Church is on board, as it seems to fit the Judeo / Christian / Muslim origin of everything: at one time, there was nothing, and then God said let there be something, and it was. Pretty cut-and-dry.
Sidebar:
I’ve always wondered how, on “The First Day”, God created the Light, but it wasn’t until Day 4 that the sun and moon were created. (Genesis 1:3-19)
Take a look at this image: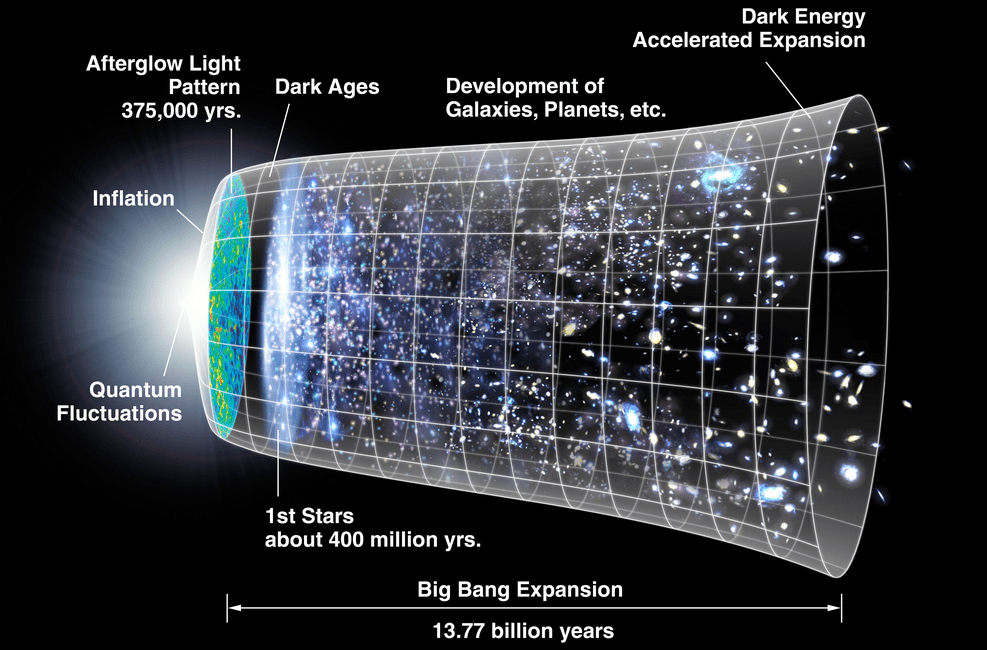 (Source)
(Source)
Apparently after the Big Bang, there was a period of darkness, called, appropriately enough, The Dark Age. And then the sun and moon were “formed”. Huh.
The scientific community recognizes – as scientific law – the conservation of mass-energy, which states that matter cannot be created or destroyed, it can only change forms. (Burning a log doesn’t “destroy” the matter, but rather turns it into heat, water vapor, carbon, carbon dioxide, etc.)
But, the scientific explanation for the origin of the universe has to break that rule, as well as a few others. Without going too far down the astrophysics rabbit hole, relying on the Big Bang theory from a strictly-scientific point means that matter just spontaneously created itself out of nothing.
Discovery Go (the online portal of The Discovery Channel) kicked off their Curiosity series with a premiere featuring Stephen Hawking. The episode argues that God isn’t necessary to start off the Big Bang, and to make their case, they use the analogy of digging a hole in a flat piece of ground: If you’re trying to create a hill from a non-hill, you can simply do so by creating an “anti-hill” (a.k.a. a “hole”) and that would produce a hill. So, according to Mr. Hawking, matter could spontaneously create itself, as long as there was antimatter of an equal and opposite mass also created at the same time.
Why?
Because according to Newton’s Third Law of Physics, every action has an equal and opposite reaction. Appropriately enough, Mr. Hawking’s analogy leaves the door open for other questions.
His analogy implies that there is a person with a shovel that digs the hole and piles up the dirt into a hill. The hole doesn’t create itself. But yet in this theory, the matter magically creates its own antimatter and, somehow, out of nothing, it gathered the energy to do that.
Taking the analogy a step further, if you put the hill and the anti-hill in close enough proximity to each other, they will return to a non-hole / non-hill / flat ground, or, in the case of the universe, nothing.
So, if this antimatter exists in the universe, there should be enough of it to completely turn all the mass of the universe into nothing… in the unfortunate case that we might bump into it, of course.
Even CERN (the particle accelerator people) recognize this… “curiosity”. According to their website, “no one has ever produced antimatter without also obtaining the corresponding matter particles.” It seems that somewhere out there, there should be enough anti-matter lurking to destroy the universe, right?
Sidebar:
Antimatter isn’t as mysterious as it sounds. In normal atoms, the nucleus has a positive charge, and the electrons spinning around it have a negative charge. In antimatter atoms, the nucleus has a negative charge, and the “electrons” spinning around it have a positive charge (thus they’re called “positrons”.) When the matter and antimatter atoms meet, they physically disappear and release energy. I have no idea how that “disappearing” is supposed to work. Apparently, the potassium in bananas causes them to give off antimatter (in very small quantities, obviously) that lasts a fraction of a nanosecond.
So scientists have observed anti-matter, but they haven’t come anywhere close to finding a sufficient quantity to swallow up the universe. Maybe not even a whole banana. And no, before you ask, the vacuum in space doesn’t count, because that’s just nothingness. Black holes don’t count either, because those are actually matter in very dense states, and even though they absorb things, they don’t turn it into nothing, they just crush it. So, believing in the spontaneous generation of all Universal matter out of nothing is a big logical assumption that the scientific theory has to make, and it breaks at least one major scientific law.
Next week: bringing forth life on a lifeless planet.
